Today I’d like to show you how to set up text-output language learning models (LLMs, or “AIs”) to run locally, on your own hardware, without any subscriptions or accounts required. If you’re worried about costs or privacy, running open-source models locally is a great way to learn LLM usage, or even to use these tools professionally if you don’t require cutting edge or massive models.
You’ll need to install two software programs for this. Both of these programs are fully cross-platform, running on Windows, Mac, and Linux.
The first, Ollama, is a command line tool that allows you to download, install, and run various open source models, listed here.
For writing prompts, we’ll be using Msty, which provides a nice graphical user interface for this. Msty does have a paid option for commercial licenses, more advanced search options, and a few other niceties, but is otherwise currently free to download and use.
Once you’ve downloaded and installed both programs according to the instructions for your operating system, you’ll want to use Ollama to install models locally on the command line. Here are some examples:
$ ollama pull gemma:1b
$ ollama pull llama2-uncensored:7b
$ ollama pull qwen2.5-coder:7b
While Msty is capable of installing and running models directly from its interface, I found this feature to be broken for me on Linux. Using Ollama for installing and running the models also allows you to use other front end programs, should you wish to not be tied to Msty.
The next step is to integrate Ollama into Msty. To do so, go to Settings (gear icon on lower left corner) -> Local AI -> Local AI Service -> Models Directory. Click on the edit icon of Models Directory, and choose the directory location where Ollama stores your models. Default model paths for operating systems are documented here.
Note: I ran into some trouble trying to use the default models path for Linux, and had to set it to /home/yourusername/.ollama/models on my Pop!_OS installation.
Finally, after integrating Ollama into Msty, you’ll want to ensure that the models are using your GPU, instead of your RAM, since the GPU is faster. Verify this by looking at the command line output for ollama. You should be able to see both the location of your Ollama models directory, as well as your GPU information. A properly set up GPU in Ollama will be displayed in a message like the one below:
$ systemctl stop ollama
$ ollama start
...
... OLLAMA_MODELS:/home/yourusername/.ollama/models ...
...
time=2025-05-29T13:50:36.129-03:00 level=INFO source=amd_linux.go:386 msg="amdgpu is supported" gpu=0 gpu_type=gfx1102
time=2025-05-29T13:50:36.129-03:00 level=INFO source=types.go:130 msg="inference compute" id=0 library=rocm variant="" compute=gfx1102 driver=0.0 name=1002:7480 total="8.0 GiB" available="7.0 GiB"
Nvidia GPUs should work out of the box. AMD GPUs may require the installation of additional packages or drivers. Information on this can be found under the “Getting Started” section of the Ollama documentation, in particular the “Linux Documentation” and the “Windows Documentation”.
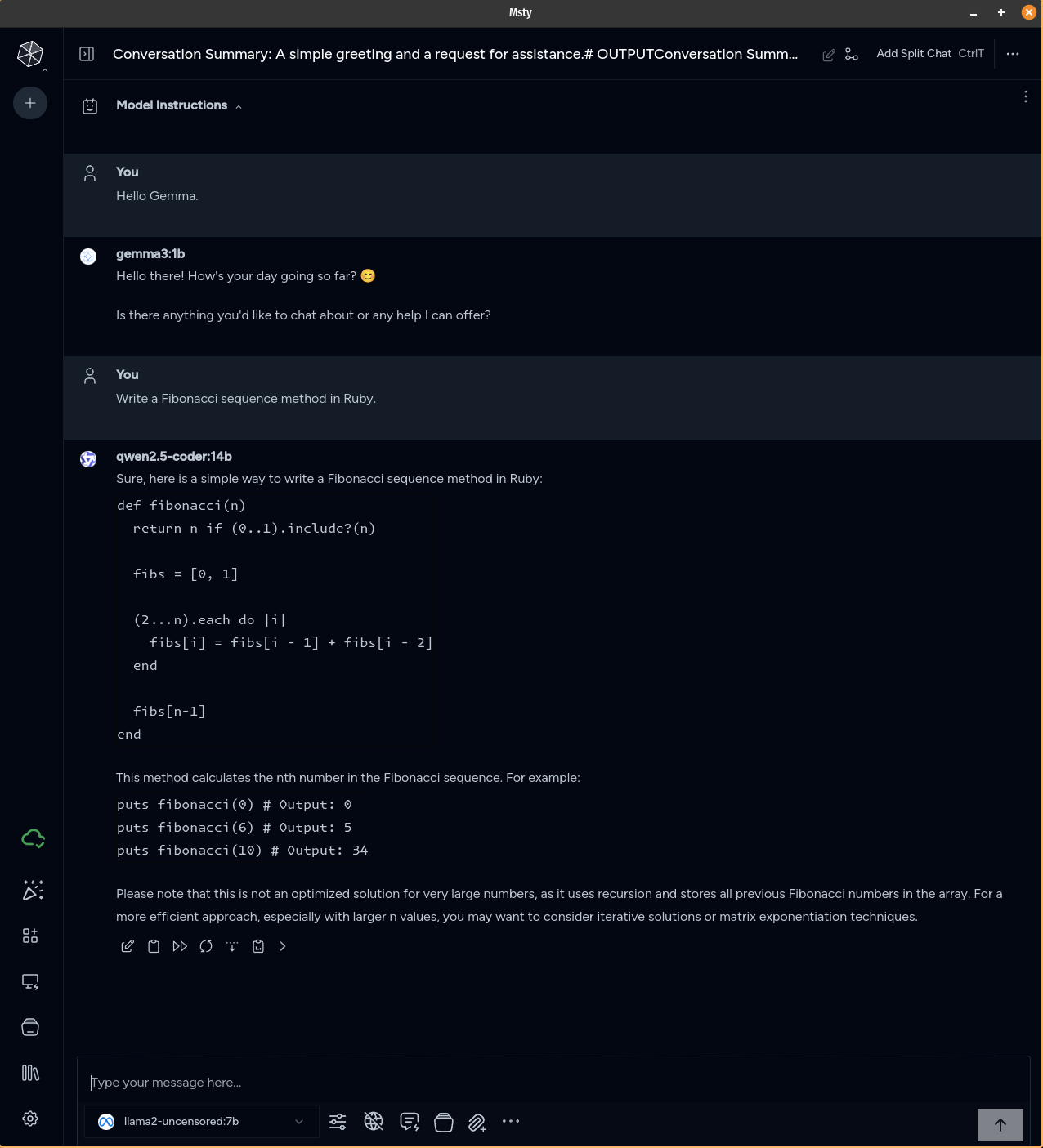
Now we are ready to have some fun!
While Ollama is running in the command line (ollama start), close and reopen Msty. If all has gone well, you now have multiple selectable models from a dropdown menu in the lower left area of the screen.
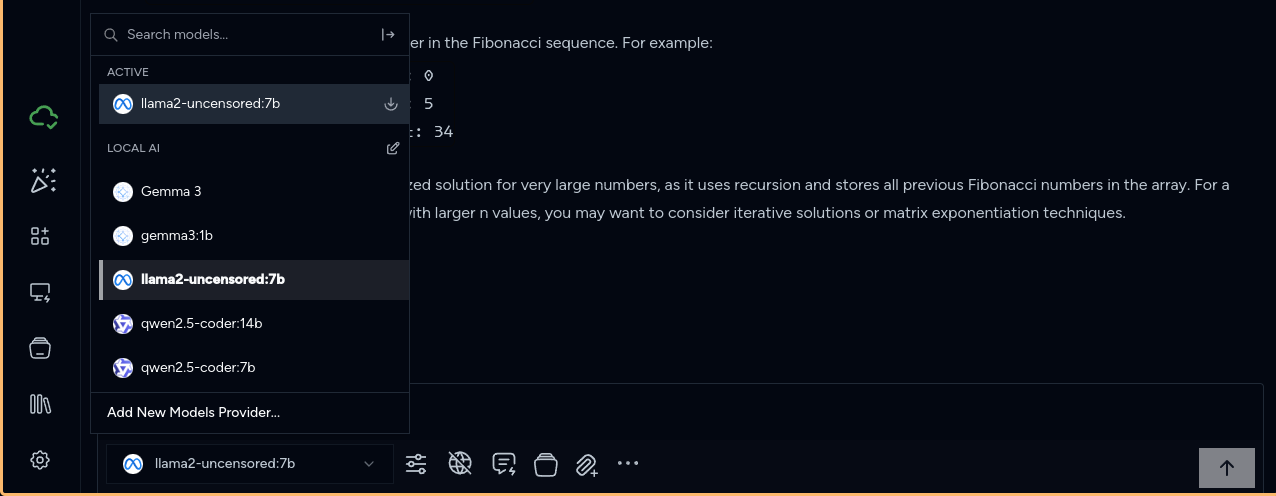
Enjoy playing with your new locally installed and free LLMs!
No LLM tools were used in the writing of this blog post. It was fully conceived, hand-typed, and edited by a real, flesh and blood, organic human being. Friends don’t let friends allow LLMs to atrophy their minds.